最近准备学习数据分析技术,感觉相当的实用,做为一个学习计划抽出来学习下,最近大块时间不多,隔断时间会作些笔记更新。
数据分析就是要分析数据得出一些结论,从而做出正确的决策。当然,这些分析思路并不在本笔记中,有时也发表下个人观点,尽量以实例进行说明。如果想自学,推荐自行看书或MOOC,个人推荐《商务与经济统计》,推荐的理由是里面的讲解与习题大部分都是实际生活的统计应用,非常适合开展思路与练习。
从商业数据开始说起,这个Excel文件是一份比较普通的销售记录中随便抽取的100行,数据的结构说明如下面的:
| 列数据 | 说明 |
|---|---|
| Customer | 编号 |
| Type of Customer | 顾客类型:普通/促销 |
| Items | 购买件数 |
| Net Sales | 净销售额 |
| Method of Payment | 支付方式 |
| Gender | 性别 |
| Marital Status | 婚姻状况 |
| Age | 年龄 |
本篇主要是利用python的matplotlib去做一些图,首先把这些引入先放执行,并把文件读出来。这里有Matplotlib的示例,可以根据自己要画的图形去看,库功能挺多的,会活用就非常强大。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
file = pd.ExcelFile('PelicanStores.xlsx')
data = pd.read_excel(file, sheetname='Data')
说明下,本人从来没有学过python,大多数代码都依葫芦画瓢,各种API都不熟悉,请不要指责代码写的太菜。python编辑器推荐spyder,本人主业是java,很自然的在与intelj师出同门的pycharm上做了不少无用功,刚用时觉得还不错,后来用了spyder后感觉太爽,当然,有些pycharm的便捷性就得舍弃了。
默认的matplotlib生成的图片有些丑(默认参数,当然支持扩展了),这里先定一些扁平化的色彩,以保证等下截的图片还看的下去,其它的图片优化就不管了。
COLORS = ['#FF22A3', '#BF52F6', '#6D52F6', '#5297F6', '#52D0F6', '#54F652', '#D5FF55', '#FFFF55', '#FFDD55', '#FFBB55','#FF9955']
目前仅使用非常基础的功能绘基础的几种图:饼图,线图,柱状图,散点图,箱形图,今天先说前四种,箱箱型图涉及一些概念下一章再说。
饼图
饼图一
饼图是非常常见的一种图,又称环形图,饼图可以非常明显的表现出数据的分布情况,饼图一般用于展示数据表中单行或单列中各种不同的数据占总大小的占比
比如这里画个饼图,表现出顾客的年龄分布状况。首先使用最原始的方法,根据需要显示的组宽度计算这100个顾客的年龄分布,这100顾客最大年龄为78,最小为20,分5组,那么,组宽应该是 58/5 = 12。代码如下:
# 定义分组函数
def get_counts_quantiative(arr, width):
'''
根据数据及组宽度切分,group一个数组
:param arr: 需要绘制的数组
:param width: 绘制数据的宽度
:return: 分开后的Label及各Label对应的数量
'''
minValue = min(arr)
maxValue = max(arr)
rangeValue = maxValue - minValue
step = rangeValue / width
if rangeValue % width != 0:
step = step + 1
labels = [''] * width
sizes = [0 for i in range(width)]
for i in range(0, width):
labels[i] = "%d - %d" % ((minValue + step * i), (minValue + step * (i + 1)) - 1)
for x in arr:
diff = x - minValue
sizes[diff / step] = sizes[diff / step] + 1
return labels, sizes
# 使用matplotlab绘制饼图
width = 5
labels, sizes = get_counts_quantiative(data['Age'], width)
exp = [0.05 for i in range(width)]
exp[2] = 0.2
plt.pie(sizes, labels=labels, explode=exp, autopct='%1.1f%%', startangle=90, shadow=True, colors=COLORS[:len(labels)])
plt.axis('square')
plt.title('Age ')
plt.show()
可以得出结果如下:很清楚的看出,32-43,44-45年龄段的消费者是最多的。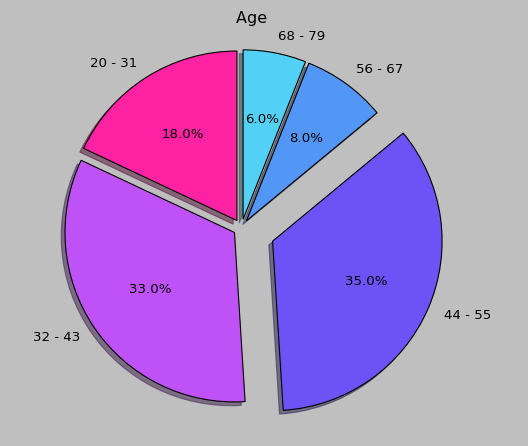
饼图二
之所以使用python就是因为它简单,自己写了那么多代码才绘出一个饼图很显然太影响效率,实际上,用了pandas后,一个饼图一行代码就可以搞定啦
pd.cut(data['Age'],5).value_counts().plot.pie()
plt.show()
结果如下,虽然有点丑,但可以根据API的一入参去调节,由于没有设置参数,自动将label处理为31.6-43.2这样的区间了,如果何用参数定义下饼显示的一些变量,显示效果应该也可以很不错。
代码里面可以看到cut方法与value_counts的结合就完成了我们上面那个自己写的方法的全部内容,pandas又内置了plot的相关方法。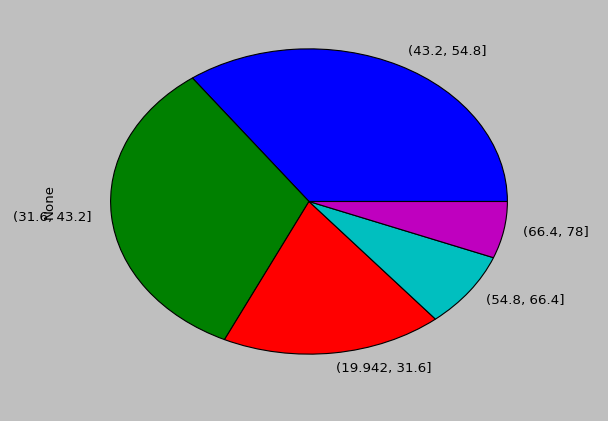
饼图三
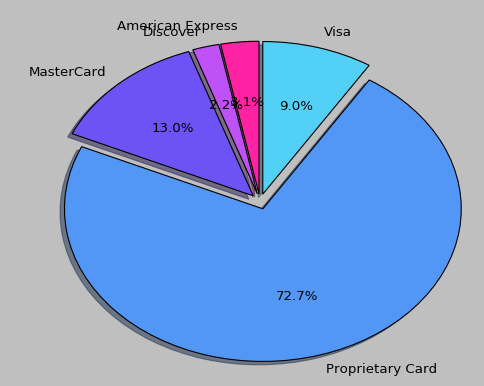
pie3 = pd.DataFrame(data,columns=['Method of Payment','Items']).groupby('Method of Payment').agg(lambda x:sum(x))
plt.pie(pie3['Items'], labels=pie3.index, explode=[0.05 for i in range(len(pie3['Items']))], autopct='%1.1f%%', startangle=90, shadow=True, colors=COLORS[:len(data['Items'])])
plt.show()
这边饼图是用来显示使用各种付款方式的购物数量,结果也很明显的可以看出使用Proprietary Card支付方式的顾客最多,这里使用的是pandas的DataFrame的一些相关参数,代码也很简单。
条形图
条形图,有的也叫柱形图,条形图的用处很多,一般用来将变量、事务分类,可以清晰的看到同类数据的详细情况
这里假设刚才导入的100条数据是来自4个不同的分店,这里根据四个不同的店的情况,绘制一张每个店销售给不同性别用户的销售额。
width = 0.5
fig, ax = plt.subplots()
shopCount = 4
x = np.arange(shopCount)
y1 = np.arange(shopCount)
y2 = np.arange(shopCount)
shopSales = len(data) // shopCount
for i in range(0, shopCount):
shop = data[i * shopCount:(i + 1) * shopCount].groupby("Gender").agg(lambda x: sum(x))
if 'Male' not in shop['Net Sales'].keys():
y1[i] = 0
else:
y1[i] = shop['Net Sales']['Male']
if 'Female' not in shop['Net Sales'].keys():
y2[i] = 0
else:
y2[i] = shop['Net Sales']['Female']
male = ax.bar(x, y1, width, color=COLORS[4])
female = ax.bar(x + width, y2, width, color=COLORS[0])
ax.set_xticks(x + width)
ax.set_xticklabels(['shop1', 'shop2', 'shop3', 'shop4'])
ax.legend((male, female), ('Male', 'Female'))
plt.show()

有时条形图也可以横着画,或是不太想看数据占比的话,饼图也可以用条形图来表示:比如下面一张图是从网上截的一张条形图,就不写python代码了。
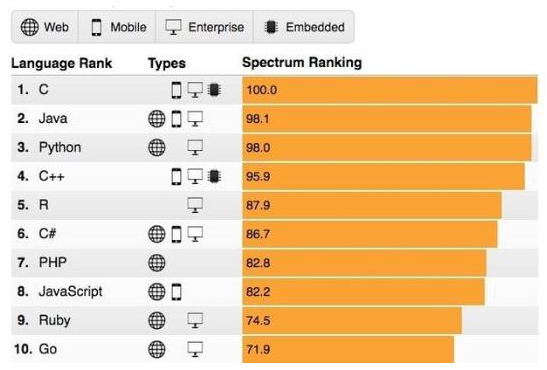
条形图绘制出来后,可以很清晰的看到基本上都是女性顾客,店面4的男性顾客偏多。条形图适用范围比较广,也可以对单个值做突出比较。
折线图
折线图也是最基础的图形,折线图一般用来表示一个变量对另一个变量变化的趋势影响(大部份时候是时间,当然也有时用累计曲线表示一个变量的完成情况)
回到刚才的例子,假设这100条数据不是4个店的数据,而是最近4个月的数据,每个月25条,那么,这个图应该这么画。
monthCount = 4
monthSale = np.arange(monthCount)
for i in range(0, monthCount):
monthSale[i] = max(data[i * monthCount:(i + 1) * monthCount]['Net Sales'])
fig, ax = plt.subplots()
# plt.xlim(0, len(test_data1['Year']) - 1)
plt.xlim(0, monthCount - 1)
plt.ylim(40, 200)
ax.set_xticks(range(0, monthCount, 1))
ax.set_xticklabels(['March', 'April', 'May', 'June'])
plt.plot(range(0, monthCount, 1), monthSale)
plt.show()
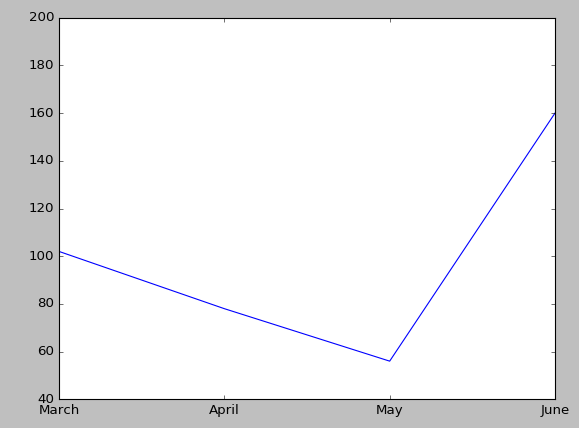
折线图可以比较清晰的看到近四个月销量上变化,一般可以根据不同产品,店面,区域等变量,多根曲线反映在一个图上,更有表现力。
散点图
散点图平时比较少见,但对于数据分析来说应该是非常重要的,远比前面几种图要种要,散点图可用来分析两个变量的的相关性,后面会说到这个相关性的专业计算方式。
这里看一下商品购买的数量与销售额的关系的散点图,使用pandas,非常简单的一行代码即可:
data.plot('Items','Net Sales',kind='scatter')
plt.show()

图中的红色箭头是我截图的时候加上去的,从图中的趋势可以看到,商品的购买数量与销售额是正相关关系。
这里可以看到pandas确实很强大,为了理解原理,先用手打出来,后续都可以直接用pandas的API去生成图,几十行代码一两行就可以搞定了。
茎叶图
茎叶图是一种用手画的图,如果用电脑程序则没有必要画这种图,有的时候没有电脑的时候,拿出一张纸,一支笔,就可以了,详细画法可以去Google一下。茎叶图的作用应该算饼图与条形图的合体,受饼图的约束(只能绘制一个变量),又可以画出条形图的形状(画好了后旋转90度),另茎叶图比条形图更能反映出数据的具体分布情况,即使有电脑可用的时候,对简单的数据也不妨画一茎叶图。